

前段时间有个想法,就是自己想开发一个fcp7字幕转srt字幕的软件,这几天有时间就开始搞了一下。主程序前后大概用了一天时间写完。主要是自己不懂python编程语言和编程,可以说完全是0基础。边写边查边学用python3写了个程序。下面我来记录一下遇到的问题和参考资料。
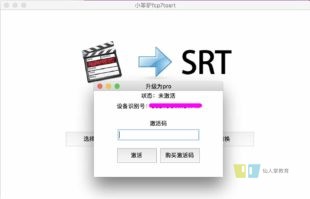
先送上一张程序最总的效果图吧
学习python基础
参考:
上学完其中一个,你就对python了解了,也能实现自己的想法。
主要用到功能:
函数,字典,保存文件打开文件,循环,判断,字符串拆分与合并,帧数转时间格式,xml文件解析
函数:
def fcp7tosrt(url):#20190117
global a_dict # 定义为全局变量 函数之间互动
print(url+"你好时间")
解释
#def“py定义是函数” fcp7tosrt"函数名称"(url“函数参数”):
程序内容
运行:fcp7tosrt(“仙人掌”)。屏幕打印仙人掌你好呀
帧数转时间格式:
#帧数转换时间
import time
def fps2srttime(fps, tb):#定义函数
fps = int(fps)#帧数转数字类型
tb = int(tb)#帧数率转数字类型
s = fps // tb # 读出秒数整数,余数另外算
ms = ((fps % tb) / tb) * 1000 # 取余数再平分帧数*1000等于毫秒
ms = int(ms) # 毫米变成整数 .zfill(3)把1变成001 需要字符串
tms = time.strftime("%H:%M:%S", time.gmtime(
s)).__str__() + "," + (ms.__str__()).zfill(3) # time.strftime("%H:%M:%S", time.gmtime(s))把秒变成时间
return tms # 函数返回最终的数字
xml解析:
刚开始用DOS解析,发现效率很慢,最后换成ElementTree解析xml文件
读出文件,解析根。通过.iter找到元素,找到了返回一个数组,一层层往下找xml相当于以。.findall(“start”)[0].text在找到最总的标签,读出标签内容。
参考:
SRT字幕:
毫秒如果不是三位数有些播放器不能识别。
1 00:00:02,160 --> 00:00:12,160 下三分之一处-样本文字 1 下三分之一样本文字 2 2 00:00:14,400 --> 00:00:24,400 垂直滚动-样本文字 3 00:01:05,640 --> 00:01:15,640 空心字模板 4 00:00:27,600 --> 00:00:37,600 打字机-样本文字 5 00:00:52,800 --> 00:01:02,800 水平滚动-样本文字 6 00:00:39,560 --> 00:00:49,560 标准文本-样本文字 参考:字幕格式
文件保存:
def saveSrt(file_name, contents):
fh = open(file_name, 'w',encoding='utf-8')
fh.write(contents)
fh.close()
好了主程序大概就用到这些东西。
软件推荐:视频转文字(支持音频提取和ocr 提取)
0回复从0开发一个带有gui界面的python笔记"